
我们常常在AI中问问题,那你们有没有想过它背后的推荐机制是什么?
在接到类似“推荐一双好的足球鞋”这一请求时,它是怎么工作的?
第一步:提问理解
自然语言理解:ChatGPT 解析用户问题,识别关键词(比如“足球鞋”、“好”、“推荐”),并理解隐含需求,如性能、脚型或预算偏好。
Prompt 构造:生成内部 prompt(或 few-shot 示例),明确输出格式,例如“列出3款足球鞋,说明适用场地、主要优缺点”。这也是为何学术研究中常使用不同 prompt 模板来定义推荐任务
这里的Prompt构造,其实涉及到AI的一个底层处理机制,就是当你问问题的时候,它自己内部会生成一个prompt。
这里说的是:
- ChatGPT 在理解你的问题后,有时会在内部自动“构造”一个更明确的问题格式
- 或者开发者提前设计了示例,即多个“示范案例”,来教 ChatGPT “推荐类问题应该怎么回答”
举个例子:
如果你输入:
给我推荐几款适合控球型中场穿的足球鞋
ChatGPT 内部可能会“翻译”成:
也就是说:ChatGPT 在处理推荐任务时,往往会自动或根据训练示例生成一个结构化的回答方式,比如:
总的来说就是
当你让 ChatGPT 推荐足球鞋时,它会:
- 先理解你的请求
- 自动构建或参考已有的“prompt 模板”(尤其是 few-shot 示例)
- 用结构化的方式回答,例如列出3款鞋,并标出每款鞋的使用场地和优缺点
那么核心点来了,我是卖球鞋的。我如何描述关于我球鞋的内容才能命中它(GPT)构建prompt提到的关键的点?
如何写出球鞋描述内容,让 ChatGPT 在用户提问时自动抓取并推荐我的产品
换句话说:你不是在让 ChatGPT 随便推荐,而是希望它**“记住你的鞋”、“优先推荐你的鞋”**,因为你提供的内容已经命中了 GPT 推荐类任务常见的 提示词 模板结构。
GPT 推荐系统的本质:
GPT 在处理推荐任务时,其实是靠“示例记忆 + 模板匹配 +语言逻辑”来决定推荐哪款鞋。
所以,你写的鞋子描述内容必须具备一定格式、维度和用词,才更容易在用户问“适合控球的足球鞋”、“800元以下的草地球鞋”时,命中 ChatGPT 内部的“推荐逻辑”。
你要给 ChatGPT 的语言模型“喂入”这种结构化内容:
比如
它命中了 GPT 推荐模板提示词的常用结构维度,也就意味着:
- 用户在问:“推荐几款适合人造草地的鞋”时 → 模型会调用你写的“适用场地”
- 用户问:“预算在500元左右” → 模型能识别你写了“预算区间”
- 用户问:“适合青少年穿的” → 模型看到“球员类型:青少年”而推荐你的鞋
你越明确地写清楚这些字段,模型越容易用语言逻辑推断你这款鞋是合适的。
下面这类语句很容易被 GPT 拿去当成“推荐理由”生成内容。
你可以在你的网站、商品页、品牌宣传中,用以下 prompt 风格介绍产品
这款鞋适合什么场地、什么预算、什么脚型、什么位置的球员?它的主要优势和用户评价是什么?
用上面结构填满,就像是你在给 ChatGPT 提供 few-shot 示例。它越“能理解”,越容易在推荐任务中选中你。
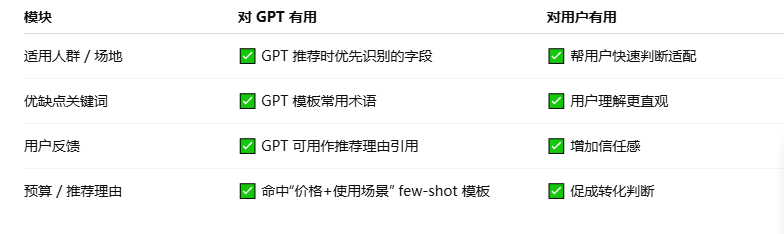
下面专门梳理一个球鞋的产品页描述作为参考:
为什么这个模板有效?
第二步:数据获取
- ChatGPT 并非直接连接数据库,也不只是凭记忆给出答案;在“购物”模式下,它通过抓取互联网上的用户评论、专业评测、论坛讨论等,构建推荐依据。
- 这些来源包括 Reddit、专业评测网站(如 FourFourTwo)、视频评论、TikTok 社区内容等,它会以“用户怎么评价这款鞋”为核心,而不是基于付费排名。
第三步:推荐逻辑(Embedding + 相似度 + 排名)
Embedding 向量表示:将每款鞋的描述、用户评论等文本信息转换为高维向量(embeddings);同理,解析用户需求的向量表示。参考:https://norahsakal.com/blog/chatgpt-product-recommendation-embeddings/?utm_source=chatgpt.com
- 相似度检索:比较用户需求向量与鞋款向量的余弦相似度,初步筛选候选鞋款。
- Ranking 阶段:对候选列表进行打分排序,考虑:
- 社区口碑强度(正面负面评价比例);
- 功能适配性(例如硬地/草地、控球/速度型);
- 近期热度(新品 vs 热卖);
- 用户需求契合度(预算、脚宽等)。
- 这一步骤常使用类似协同过滤、内容过滤的混合模型。
第四步:解释式输出
ChatGPT 会不仅仅给出鞋名,还会生成简洁的理由说明,比如技术特点、适用场地、优缺点、价格区间、用户反馈摘要等。
除了推荐,还能结合上下文给方案选择建议,如“适合宽脚型”、“适合速度型前锋”等。

没有回复内容