发布
发布文章
创建话题
创建版块
发布帖子
开通会员
开通黄金会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通黄金会员
开通钻石会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通钻石会员
开通会员 尊享会员权益
登录
注册
找回密码
开通会员 尊享会员权益
登录
注册
找回密码
分享
创建新版块
Google
帖子 1277
互动 2286
关注 1
超级版主
申请版主
发布
全部
最新发布
最新回复
热门
精华
admin
5个月前发布
6次阅读
关注
私信
2023-04-09请问大佬们如何让shareAsale中的订单用UTM追踪,生成了UTM不知道在联盟后台哪里添加和通知Affiliate
请问大佬们如何让shareAsale中的订单用UTM追踪,生成了UTM不知道在联盟后台哪里添加和通知Affiliate
评分
1
分享
admin
5个月前发布
6次阅读
关注
私信
2024-01-04Google Search Essentials 这篇文章很棒,可以说是谷歌搜索引擎的红线,全部列出来了。 一是技术这块,要达到最基本的要求。 二是内容,不能违反谷歌的垃圾政策。 三是内容,也就是老生常谈的 E-E-A-T。 按照我的理解,只要你是在这个红线内做内容生产,怎么着都不会被惩罚,有可能算法每更新一次,流量反倒是暴涨一波。 链接:https://developers.google.com/search/docs/essentials
Google Search Essentials 这篇文章很棒,可以说是谷歌搜索引擎的红线,全部列出来了。 一是技术这块,要达到最基本的要求。 二是内容,不能违反谷歌的垃圾政策。 三是内容,也就是老生常谈的 E-E-A-T。 按照我的理解,只要你是在这个红线内做内容生产,怎么...
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2023-07-29我的标准购物广告去年还跑挺好的,但是由于断货的原因停了几个月,再次开启的时候原来的预算跑不出去了,每天跑出去的只有原来的十分之一,我应该提高点击价格吗?还是还有其他可能出现的问题?
我的标准购物广告去年还跑挺好的,但是由于断货的原因停了几个月,再次开启的时候原来的预算跑不出去了,每天跑出去的只有原来的十分之一,我应该提高点击价格吗?还是还有其他可能出现的问题?
评分
1
分享
admin
5个月前发布
6次阅读
关注
私信
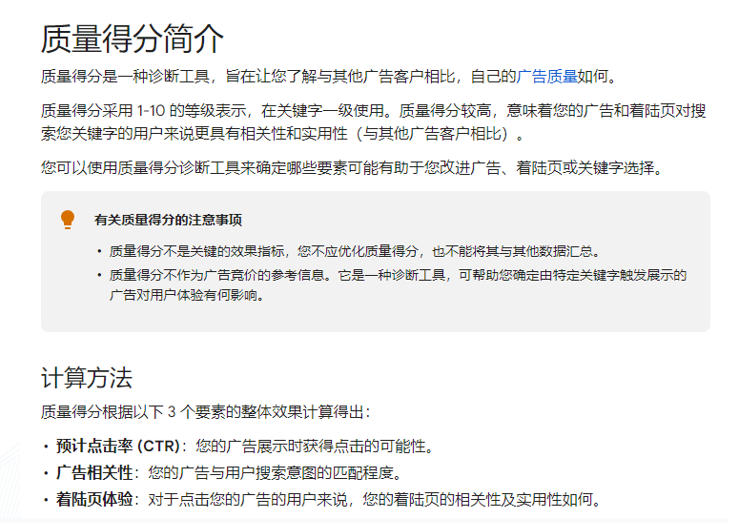
2023-06-16关于谷歌广告质量得分的深度思考
首先,遇到一个专有名词,第一时间找官方的文档说明,比如
官方链接,有根有据:
https://support.google.com/google-ads/answer...
评分
回复
分享
admin
5个月前更新
6次阅读
关注
私信
2023-05-15想问下广告出现受定位条件限制是什么意思呢?应该怎么优化
想问下广告出现受定位条件限制是什么意思呢?应该怎么优化
评分
4
分享
admin
5个月前发布
6次阅读
关注
私信
2023-11-01 这篇文章将外链讲透了,其中的七种类型外链建设的方式,可以学习一下,然后结合自己的情况做一个 SOP 出来。 链接:https://ahrefs.com/blog/white-hat-link-building-techniques/
这篇文章将外链讲透了,其中的七种类型外链建设的方式,可以学习一下,然后结合自己的情况做一个 SOP 出来。 链接:https://ahrefs.com/blog/white-hat-link-building-techniques/
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2022-03-13 GDN展示广告测款策略
Campaign设置:
1.投放目标:销售
2.预算设置:先以10美金/天
3.转化设置:设置“add to cart”和“Purchase”为测试campaign级...
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2023-09-13你好,我现在有个任务是在新品发布的时候,在GOOGLE开启CTV广告,但我不知道怎么去选择CTV广告。你能告诉我嘛?
你好,我现在有个任务是在新品发布的时候,在GOOGLE开启CTV广告,但我不知道怎么去选择CTV广告。你能告诉我嘛?
评分
1
分享
admin
5个月前更新
6次阅读
关注
私信
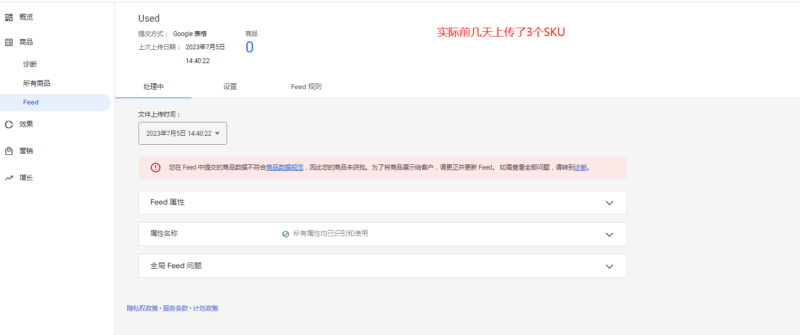
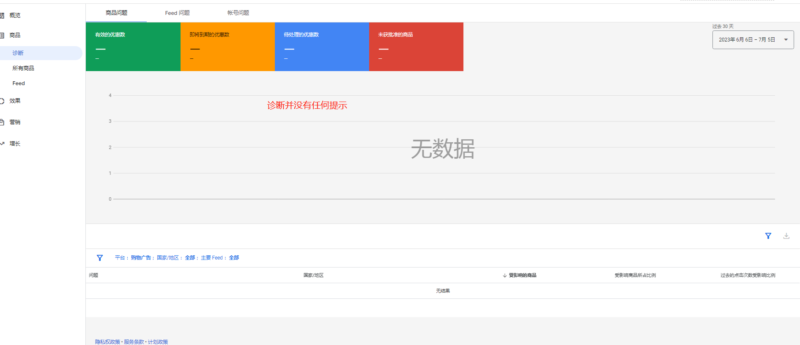
2023-07-05请教,新GMC商城产品几天了,商品数量显示以为为0,系统提醒查看诊断,里面也没有啥提示,怎么办?
请教,新GMC商城产品几天了,商品数量显示以为为0,系统提醒查看诊断,里面也没有啥提示,怎么办?
评分
2
分享
admin
5个月前发布
6次阅读
关注
私信
2023-07-28 使用补充feed更新产品标题、描述和自定义标签4。 广告系统可以通过自定义标签4进行定位了,也就是补充feed显示提取成功,并于系统更新了。 但几天时间了,发现广告系统还是显示原来的标题,这个有什么解决的办法吗?
使用补充feed更新产品标题、描述和自定义标签4。 广告系统可以通过自定义标签4进行定位了,也就是补充feed显示提取成功,并于系统更新了。 但几天时间了,发现广告系统还是显示原来的标题,这个有什么解决的办法吗?
评分
3
分享
admin
5个月前发布
6次阅读
关注
私信
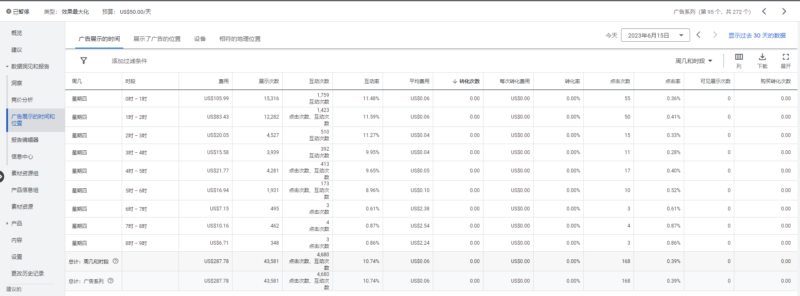
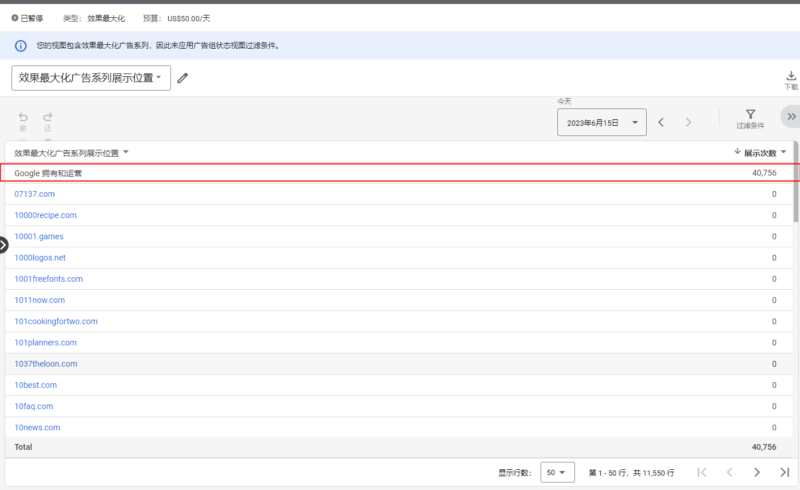
2023-06-15 你好!我们最近的pmax广告系列又遇到了类似的问题了,就是pmax广告莫名其妙的花费到了其他地方去了,导致今天出现了巨额的花费,我们很早就按照图帕先生您给的建议移除了所有的app,然后将详情页锚定在我们推广的页面上了,但是这个情况还是发生了,请问有什么办法可以完全避免这个发生吗?
你好!我们最近的pmax广告系列又遇到了类似的问题了,就是pmax广告莫名其妙的花费到了其他地方去了,导致今天出现了巨额的花费,...
评分
1
分享
admin
5个月前发布
6次阅读
关注
私信
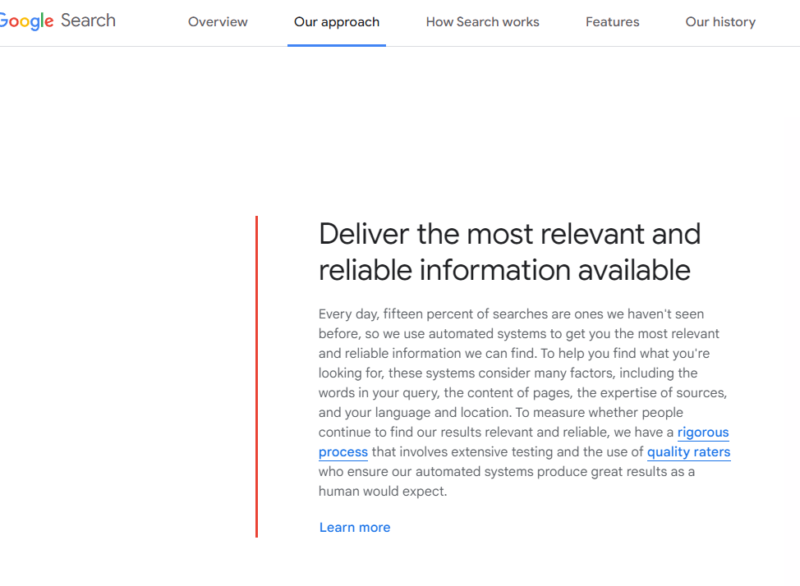
2023-12-30 Get your website on Google 这篇文章主要是关于谷歌收录,侧重于检查内容是否收录的方法以及相应的检查清单。 文章中明确说了,谷歌会自动收录内容并将其索引收录,不需要我们做额外的动作。 但每天的内容很多,难免会有网页被遗漏掉。 所以除了一些手动收录提交的动作外,还可以去看看谷歌对各个部分内容的要求。 链接:https://developers.google.com/search/docs/fundamentals/get-on-google
Get your website on Google 这篇文章主要是关于谷歌收录,侧重于检查内容是否收录的方法以及相应的检查清单。 文章中明确说了,谷歌会自动收录内容并将其索引收录,不需要我们做额外的动作。 但每天的内容很多,难免会有网页被遗漏掉。 所以除了一些手动收录...
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2023-07-18pmax广告单独排除品牌词或竞品词的功能终于出来啦!
品牌关键词设置可应用于搜索和Performance Max广告系列,根据广告需求引导或排除特定品牌流量。
在搜索广告,品牌限制会将流量限...
+12
评分
回复
分享
admin
5个月前更新
6次阅读
关注
私信
2023-06-05我们网站的GA最近这几天出现了异常情况,就是user和click统计数据差异巨大,和之前相比有大幅度的下降,请问这个是转化代码出了问题吗?还是其他原因
我们网站的GA最近这几天出现了异常情况,就是user和click统计数据差异巨大,和之前相比有大幅度的下降,请问这个是转化代码出了...
评分
3
分享
admin
5个月前发布
6次阅读
关注
私信
2023-04-04 最近转化好滴啊,持续好长时间了,从二月到现在一直都在下降,越来越差了,即使广告Troas上调了很多也无济于事,都达不到目标值,对比去年这个时候效果差了非常多,现在很迷茫,到底什么原因呢?
最近转化好滴啊,持续好长时间了,从二月到现在一直都在下降,越来越差了,即使广告Troas上调了很多也无济于事,都达不到目标值,对比去年这个时候效果差了非常多,现在很迷茫,到底什么原因呢?
评分
1
分享
admin
5个月前更新
6次阅读
关注
私信
2024-07-15 上周有跟知乎的前 SEO 负责人聊一下午,分享下重点。 因为他们主要是做百度,谷歌只是附带着做,但基本逻辑差不多。 这里聊下他们是怎么分析 SERP,然后做针对性内容的。 首先就是数据抓取,就是将每一个关键词的前几页结果都抓取出来,再针对结果分析其中的共性。 比如「图一」就是某个网站在某个关键词下的排名情况,会发现其标题中基本都有「第、强、排行榜」这样的关键词。 那从这个角度出发,搜索引擎算法是青睐这种类型内容的,也就说明后续我们输出内容时,需要往这个方向靠。 「图二」则是他们的数据分析报表了,原理就是对搜索结果进行词条切片,然后分析各个词条的出现频率。 至于具体的分析方法与数据统计逻辑,没好意思问那么细(可能商业敏感)。 不过大体的逻辑基本清晰了,就是调研关键词搜索结果页面,然后数据分析页面关键词共性,再从共性出发创作「概率」大点的内容。 有了数据分析结果,下一步就需要创作相应内容了。 他们现在的方法,主要还是 AI 创作。只不过模型训练上花了不少功夫,可能并不是适合我们。 那我们作为小个体,是不是也可以从这个点出发,将 SERP 的分析结果融入到内容生成的 Prompt 里面呢?
上周有跟知乎的前 SEO 负责人聊一下午,分享下重点。 因为他们主要是做百度,谷歌只是附带着做,但基本逻辑差不多。 这里聊下他...
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2023-08-31怎么提高购物广告的,我看前端用的基本都是白底图,没有多大差异,但是跑出来点击率都在1%以下,服装行业。不知道同行是什么情况,有什么提高点击率的思路吗
怎么提高购物广告的,我看前端用的基本都是白底图,没有多大差异,但是跑出来点击率都在1%以下,服装行业。不知道同行是什么情况,有什么提高点击率的思路吗
评分
1
分享
admin
5个月前发布
6次阅读
关注
私信
2023-12-29 Google Search technical requirements 这篇文章重点讲了,对于网站收录而言,一些最低的技术标准是什么。 一是,网站不能屏蔽谷歌爬虫,这点在 robot.txt 文件中进行控制即可,至于具体的爬虫报告,可以在 GSC 后台里面查看。 二是,页面能正常访问,也就是从技术层面上的说的 HTTP 状态码是 200,当然速度得有一定的保障,这会对爬虫爬取效率有益。 三是,页面上有可索引收录的内容。这里的可所索引内容,主要指的是谷歌搜索引擎支持的文字性内容(也包括媒体素材),并且这些内容不能违反谷歌的垃圾政策。 其实,这篇文章读下来,都是很基础的链接收录细节,及各种概念性说明。 对于理解收录是什么,以及收录中涉及的各种技术标准,很有帮助。 链接:https://developers.google.com/search/docs/essentials/technical
Google Search technical requirements 这篇文章重点讲了,对于网站收录而言,一些最低的技术标准是什么。 一是,网站不能屏蔽谷歌爬虫,这点在 robot.txt 文件中进行控制即可,至于具体的爬虫报告,可以在 GSC 后台里面查看。 二是,页面能正常访问,也就是...
评分
回复
分享
admin
5个月前发布
6次阅读
关注
私信
2023-11-16 1最近公司有采购外链的需要,想做一些Haro外链,在Fiverr上看了一圈不知道靠不靠谱想问一下,这方面有好的agency推荐吗
最近公司有采购外链的需要,想做一些Haro外链,在Fiverr上看了一圈不知道靠不靠谱想问一下,这方面有好的agency推荐吗
评分
1
分享
admin
5个月前发布
6次阅读
关注
私信
2023-08-22 你好,我的品牌词搜索广告数据非常差。。比我的常购物广告要差得多。请问我应该如何去分析原因以及调整?其中存在的一个问题是亚马逊的客人会经常跑到谷歌搜索我们的独立站然后问售后问题,这会浪费掉一部分的广告预算。但也不至于这么差,ROI只有零点几。。
你好,我的品牌词搜索广告数据非常差。。比我的常购物广告要差得多。请问我应该如何去分析原因以及调整?其中存在的一个问题是亚马逊的客人会经常跑到谷歌搜索我们的独立站然后问售后问题,这会浪费掉一部分的广告预算。但也不至于这么差,ROI只有零点几。。
评分
1
分享
上一页
1
…
56
57
58
59
60
…
64
下一页
跳转
归档
2025 年 6 月
分类目录
未分类
本站同款主题模板
zibll子比主题是一款漂亮优雅的网站主题模板,功能强大,配置简单。
查看详情
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册
主题模板推荐
本站采用子比主题建站
zibll子比主题是一款漂亮优雅的商城资讯类网站主题模板,功能强大,配置简单
这是一条系统弹窗通知示例
管理员可在
主题设置-常用功能-弹窗通知
中进行相关设置
了解子比主题
立即设置